Enriching the online shopping experience with Helios Recommendation Engine
Enriching the online shopping experience with Helios Recommendation Engine
Jun 26, 2023
authored by: JC Seok, Mefta Sadat, Alex Yip, Indrani Gorti, Julia Lee
Reference: Loblaw Digital
Introduction
Online shopping has been around for many years and it has become a huge part of our everyday lives. The experience continues to improve and it’s more convenient than ever to find the products you are looking for — and in some cases, products that you didn’t even know you wanted. At Loblaw Digital, our goal is to provide the best online shopping experience possible for our customers across all our lines of businesses. Part of that is providing an experience where customers are inspired and delighted by our ability to anticipate their needs. We want to recommend tailored products, and enrich their shopping experience through discovery of new ones.
Recommendations at Loblaw Digital
During the early days of Loblaw Digital, we wanted to quickly create an online shopping experience for our lines of business (PC Express™ for grocery, Shoppers Drug Mart for beauty/pharmacy, and Joe Fresh for apparel). As a result, we chose to outsource the product recommendations experience to a third party vendor so that we could launch fast.
Fast forward to last year, with the release of our very own in-house Helios Platform, we saw an opportunity to take ownership of the product recommendations experience and build an in-house platform to support this process.
Machine Learning Lifecycle Before Platform
Before implementing the platform, each of our machine learning pipelines were highly customized, which led to three major issues:
- Slower to ship: A considerable amount of time was dedicated to building and resolving issues related to serving infrastructure such as Kubernetes (k8s), containers, alerting and monitoring, and similar elements.
- Code modifications due to business requirement changes: Any change in business requirements necessitated manual code updates, resulting in additional time and effort.
- Insufficient component reusability: The components employed in our pipelines lacked the capability to be easily reused, which hindered efficiency and productivity.
Our goal with the Helios Recommendation Engine (HRE) is to solve these three issues.
What is Helios Recommendation Engine (HRE)?
HRE is an advanced MLOps tool built in-house at LD that serves as a recommendation platform, with the aim to deliver a highly scalable and reusable solution while being extremely configurable to accommodate evolving business requirements.
As an MLOps tool, HRE offers a comprehensive set of features designed to streamline the deployment and management of recommendation systems in production environments. It provides seamless integration capabilities, enabling efficient model management, serving, deployment, business-rule based filtering and re-ranking. HRE incorporates robust monitoring and alerting functionalities, ensuring comprehensive visibility into model performance and system behavior. Automated testing and validation mechanisms further enhance the platform’s reliability and accuracy. Additionally, HRE emphasizes streamlined version control and artifact governance, allowing for effective collaboration and traceability.
Architecture
Fig: HRE Platform Architecture
Core Components
Training
Within the ML Platform, we have implemented a development pattern that streamlines the creation of reusable ML pipeline code. This approach includes the introduction of an ML Training Pipeline Code Template, which encompasses a wide range of use cases, such as Batch Prediction, Custom Container Training, Matrix Multiplication, Feature Store Integration, and Writing Reusable/Shared Vertex Components.
By leveraging these templates, our MLEs can efficiently construct ML Pipelines for model training and compute recommendations. To ensure seamless integration with the HRE platform, we follow a standardized schema when writing precomputed recommendations. This standardized approach enables the HRE platform to effectively serve the recommendations using prediction servers.
As a result, our MLEs can solely focus on building and improving machine learning models, while the HRE platform takes care of serving the recommendations and the application of business rules. This division of responsibilities enhances productivity and allows our team to maximize their efforts in model development.
Profile
In the context of HRE, the recommendation carousel is referred to as profile, which is served via a REST API. Profiles are the core component that puts us in control of the recommendation carousels. Profiles offer powerful customization options:
- Customization through YAML Spec: The foundation of profile customization is the YAML specification, which serves as a structured representation of configuration details for the recommendation carousel. This specification empowers the user to tailor different aspects of the recommendation to align with specific business requirements. To simplify the process of submitting the YAML spec to the HRE API, we have developed a user interface (UI) that streamlines the submission process. By utilizing the UI, the YAML spec transforms into a dynamic input form, enhancing the user experience and facilitating seamless interaction with the platform.
- Choosing the Perfect Model: With profiles, you have the freedom to select the ideal machine learning model for generating the recommendations. The models are created by our MLEs and can be reused/customized for different use cases.
- Crafting the Recommendation Flow: In HRE, you have the power to design the recommendation flow using the inference graph by specifying the sequence and dependencies of models, creating unique recommendations tailored to the business.
- Fine-tuning Recommendations: With profiles, we can easily answer questions like
- “How many recommendations should be displayed?”
- “What is the preferred sorting mechanism?”
- “What filters should we apply to meet the business requirements?”
These configurations can all be defined as part of the profile, allowing for fine-tuning the recommendations to extract the best possible recommendations for our customers.
- Version Control and Collaboration: The core strength of the profiles is from the power of collaboration and tracking changes. HRE maintains the history of profile configurations, making it easy to track and rollback if needed. Collaborate seamlessly with developers, data scientists and stakeholders in managing the recommendations, ensuring everyone is on the same page.
Prediction Server
Within HRE, prediction servers play a vital role as the powerhouse behind deploying and serving recommender models. They offer a streamlined reusable approach, ensuring efficient and flexible integration within the platform. Here are some key aspects of prediction servers that make them an essential component in HRE:
- Simplified Model Deployment: Prediction servers simplify the process of deploying the machine learning models and serving predictions, enabling data scientists and ML engineers to focus on their core strength — model development and experimentation. These servers encapsulate the essential infrastructure required to serve the ML models created by the ML teams, abstracting away complexities and simplifying the deployment process.
- Reusability: Prediction servers are designed as a versatile component, ready to be reused across multiple use cases within the recommendation engine. This promotes efficiency, empowering our data scientists and machine learning engineers to build upon existing solutions and accelerate development.
- Flexible Integration: Prediction servers seamlessly integrate machine learning models into the HRE engine, tailoring them to various application scenarios. Whether it’s offline batch predictions or real-time serving, prediction servers adapt to meet the specific needs of the recommendations.
- Centralized Prediction Repository: Prediction servers are stored as artifacts in the HRE database, providing a centralized repository for easy management and access. Developers can add new or updated existing prediction servers to the repository, expanding the options available for users to leverage.
Model
The models in HRE are a fundamental component for configuring the deployment of machine learning models. They provide a streamlined approach for our ML teams to define and utilize the models that they created and onboard into the HRE engine. Here are some key aspects of the models:
- Simplified Model Integration: Integrating models into HRE is as easy as it gets. ML teams can register their new models by providing a simple configuration that describes how the models should be used. This registration process enables quick integration with the HRE engine, making the models readily available for use in profiles.
- Selecting the Prediction Server: With HRE’s centralized repository of prediction servers, our ML teams have the freedom to choose a prediction server that suits their needs.
- Centralized Model Repository: HRE provides a centralized repository, housing all registered models. By registering their models, ML and Platform teams make them accessible and available for us to use in the profiles for creating the recommendation carousels.
Fig: Artifact View in HRE UI
Combiner (Filter)
In the recommendation flow of HRE, Combiners play a pivotal role as a critical component. They are considered as the final stop where all recommendations converge, working to refine and transform the recommendations according to the specifications outlined in the profile. By harnessing the power of the Filter, HRE enables the creation of sophisticated recommendation algorithms that go beyond the capabilities of individual models.
- Aggregating Recommendations: Combiners have the essential task of combining recommendations from multiple models. These recommendations may come from different machine learning models, each with its unique approach and strengths. In the early phase of HRE, the combiners only support switching between two models where if one model falls short in providing the recommendation, the fallback model comes into play. In a later phase, we are looking to support aggregation and combination of both recommendations to create a diverse set of models.
- Applying Core Logic: Once the recommendations land on the combiner, it applies the core logic and business rules defined in the profile. The logic may involve sorting methods to prioritize certain recommendations based on specific criteria, filters to include or exclude recommendations based on predefined rules and fallback mechanisms to choose one recommendation model over others.
Fig: DSL for applying business rules to transform recommendations
Complex Inference Graph
The Complex Inference Graph is a powerful feature within HRE that allows users to define a flexible recommendation flow tailored to the unique needs of the business and the preferences of the users. It serves as a graphical representation of the recommendation flow, enabling users to orchestrate and customize the entire process.
With the Complex Inference Graph, users can define the sequence and dependencies of various models and filters involved in generating the recommendations. The flexibility empowers businesses to create sophisticated and personalized recommendations that best suit the business requirements.
HRE API
HRE API serves as a core orchestrator and central hub within the Helios Recos Engine, facilitating the interaction between various components, schema validation, maintaining a centralized registry of essential elements such as combiners, prediction servers and models, and powering the recommendation engines through orchestrating the profile creation.
- Centralized Component Registry: The HRE API acts as a comprehensive registry, managing all the essential components required for the recommendation engine. It handles the registration, storage and retrieval of crucial elements such as combiners, prediction servers and models. By centralizing the management of these components, HRE API ensures consistency, version control and easy accessibility and role breakdown for the entire HRE team.
- Effortless Profile Deployment: With a provided profile spec, it seamlessly creates a serving API integrated with the use of Seldon and Kubernetes. This out-of-box integration simplifies the deployment process, enabling our users to deliver recommendations with ease. The HRE API takes care of the complex details, allowing our users to focus on their expertise.
Fig: Simple user-to-HRE API interaction
Monitoring and Alerts for Profiles: To ensure optimal performance, the HRE API also takes charge of monitoring and alerting for each profile. It keeps a close eye on every profile, tracking their performance and detecting potential issues. It also integrates with powerful analytics and reporting tools such as Prometheus and GCP monitoring, providing insights into performance.
Fig: API Performance Monitoring and Alerting Dashboard
Fig: Component Level Dashboard to drill down into complex inference graph
HRE UI
The HRE UI serves as a user-friendly interface that enables easy interaction with the HRE engine. The UI is powered by the HRE API, providing an intuitive and visually appealing platform for managing the recommendation system. These are the key benefits we were able to achieve with introducing a UI.
- Effortless Profile Management: With the UI, managing profiles becomes a breeze. You can easily create, edit, and delete, tailoring them to meet specific business requirements. The intuitive interface allows configuring various parameters such as the number of recommendations, filtering criteria, and constructing the recommendation flow. This level of control empowers our users to deliver highly relevant recommendations to our customers.
Fig: HRE UI Profile Management
Preview and Testing: HRE UI offers functionality to preview and test features, providing insights on how our recommendation carousels will appear to our customers. We can explore different profile configurations and instantly see the impact on the recommendation results. This capability enables our users to fine-tune their profiles, ensuring an optimal user experience and maximizing engagement.
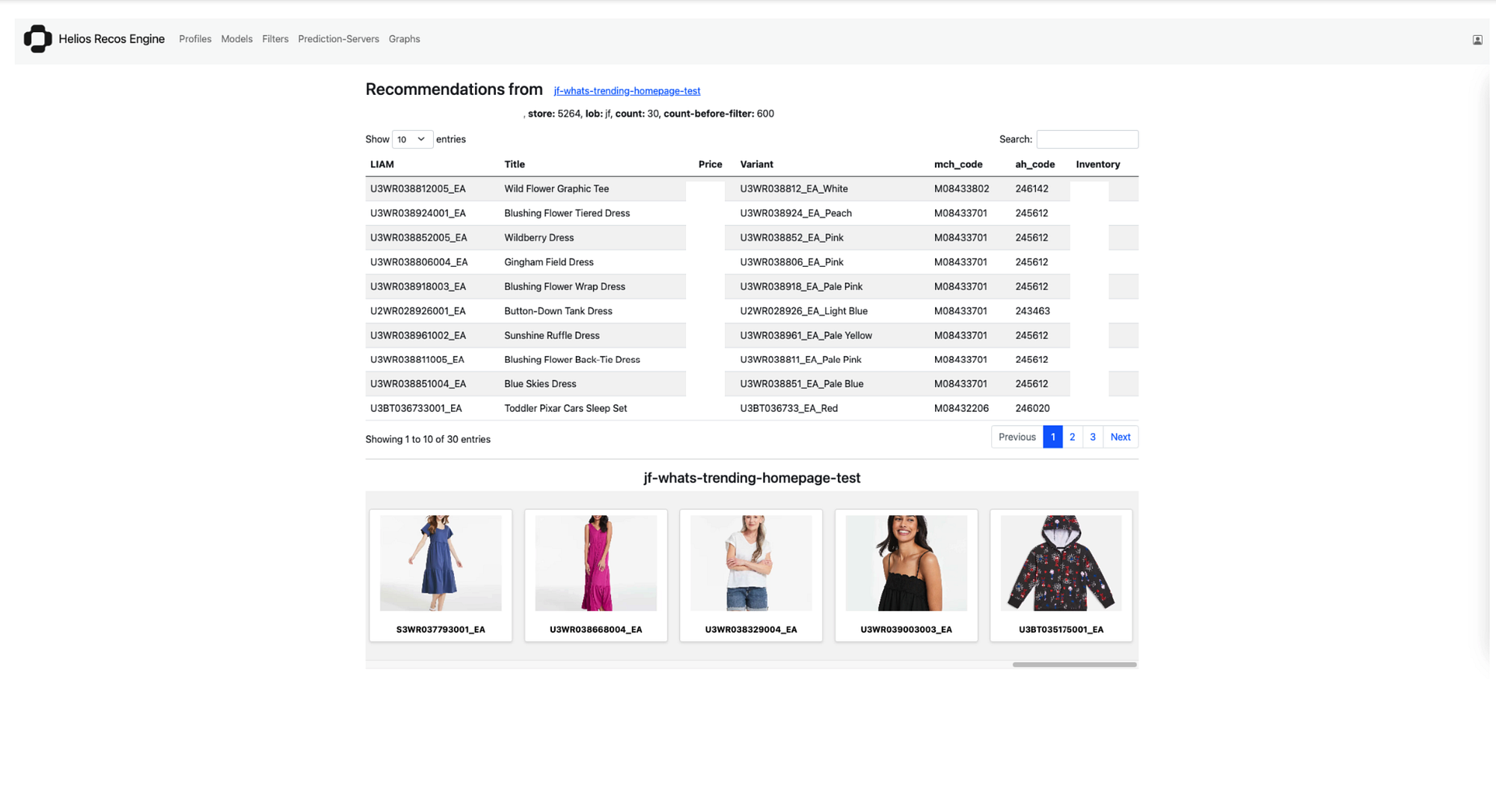
Fig: Recommendation preview and testing at Carousel Level
Collaboration and Access Control: The HRE UI supports collaboration among team members by allowing role-based access control. We define user roles and permissions, ensuring that each team member has the appropriate level of access to the HRE UI functionalities and resources. The UI promotes collaboration, enhances security and enables efficient management of the resources in the UI.
HRE CLI
The HRE CLI is a simple command-line interface that enables seamless resource management and integration with CI/CD pipeline. It enables our users to efficiently automate and manage HRE resources by maintaining infrastructure as code. With HRE CLI, users can manage their HRE resources directly from CI/CD pipelines in their repository, ensuring consistent and streamlined deployment processes. By leveraging version-controlled repositories and Git-based workflows, it promotes collaboration, efficient teamwork and standardized review processes.
Fig: Output of HRE CLI help command
Machine Learning Lifecycle After Platform
After the successful implementation of the Helios Recommendation Engine (HRE) platform, we have already witnessed significant improvements in our machine learning life cycle. Here is the overview of how the HRE has positively impacted our processes:
Streamlined Model Development: With the HRE, our data scientists and machine learning engineers can focus more on model development and experimentation. The prediction servers simplify the deployment of their models, abstracting away the infrastructure complexities and providing reusability. This streamlined approach accelerated the development cycles, enabling our teams to iterate quickly and bring new models to production faster.
Enhanced Collaboration: The centralized repository in the HRE facilitates collaboration across all teams. Each team can easily register and manage its resources, making them accessible for use by other teams. This centralized approach promotes efficient version control, coordination and knowledge sharing among teams. The HRE API and UI further enhance collaboration by providing interfaces for managing components, profiles and monitoring.
Flexible Customization: The YAML specification allows for a wide range of customization of the profiles using a custom DSL. The current infrastructure allows business users to define machine learning models, inference graphs and various parameters to construct recommendation carousels according to their specific needs. With the DSL, the users can also define types of transformations they want to apply on recommendations generated from an ML model. This flexibility empowers businesses to create relevant recommendations, improving the user experience and driving better business outcomes.
Efficient Deployment and Monitoring: The HRE API plays a pivotal role in deploying profiles and managing the components. It integrates with Seldon and Kubernetes, simplifying the deployment process and providing scalability.
Continuous Improvement: The HRE platform facilitates the continuous improvement of our recommendation carousels. We can easily fine-tune, update, and release new components such as new models or combiners based on the business requirement changes or data-driven metrics.
What’s Next?
With the launch of the Helios Recommendation Engine, we received positive feedback on the end-to-end user experience as well as many suggestions on how to further improve the platform. This is a great sign for the adoption of a new platform and we are excited to continuously build upon it to provide more functionality for future recommendation use cases.
In addition to improving the recommendation engine, we are also looking to incorporate learnings from this project back into our overall ML platform, which is currently used to power other existing ML projects. We built the core components in a way such that they are flexible and configurable, with the goal of reusability for future projects. We are looking forward to further improving the overall developer experience for our ML engineers by continuing to iterate on components of our ML platform.